Module 1: Basic Principles
Contents
Module 1: Basic Principles#
Level: Beginner (100)
Learning objectives:
Introduction to the basic principles of Linked Open Data (LOD)
Developing an understanding of how LOD is applied within heritage institutions
Introduction#
Galleries, libraries, archives and museums have traditionally collected, described and made available the heritage materials that can help us to develop an understanding of our past. To truly understand such objects, the collections that are managed by these institutions often need to be studied in conjunction. Museum objects may deepen our comprehension of library objects, for example, and vice versa. In many cases, however, such collections are still studied in isolation. What if we could actually explore our shared cultural heritage by searching all of these institutional collections simultaneously? While this possibility would simplify the work of historians and researchers in general, it would also enable them to ask more complicated and, ultimately, more interesting research questions.
The Semantic Web consists of a suite of technologies which enable us to implement such interconnectivity. Linked Open Data (LOD) form one of the central building blocks. Essentially, by making use of LOD, institutions can make their raw data available on the web. This is clearly a change from the traditional situation, in which GLAM institutions have provided access to their digital data via web pages with search interfaces. On such pages, the search options remain limited to the options that have been enabled by the builders of that website, and users can interact with these data in a mediated form only. By exposing their data as LOD, institutions can create a new layer on top of the existing web in which the raw data can be accessed and searched directly. Once the data from one collection have been made available in this raw format, they can also be connected relatively easily to data from other institutions. The core ideas underlying the Semantic Web were originally developed by Tim Berners Lee, among others. In a well-known TED talk, Berners Lee explains that the Semantic Web centrally aims to augment the existing Worldwide Web. The WWW that has been in existence since the 1990s basically consists of linked documents, but, by making use of the principles that underpin the Semantic Web, it also possible to create a global web of interconnected data.
from IPython.display import IFrame
from IPython.core.display import display
display(IFrame('https://video.leidenuniv.nl/embed/secure/iframe/entryId/1_rckqw53w/uiConfId/44110401/st/0' , width = 640 , height = 360 ))
When data are made available in a raw and unadulterated form, this can also lead to an entirely different way of searching. When people search for information in a search engine, they normally receive a list of documents which potentially contain the answers to the questions they have. They still need read these documents to find the answer to their question. If raw data are made openly available, users can be shown the answer to their question directly. The Knowledge Graph that is generated alongside Google Searches is a well-known implementation of this notion. Another important advantage of this infrastructure is that different databases can be connected much more easily. The values in one database can be linked to the values in another database. We can essentially create one big encompassing database in which different datasets can be queried at the same time.
The RDF data model#
To be able to query different databases simultaneously, the formats of these databases need to be harmonised. The technology underlying the Sematic Web aims to represent all the values that can be found in databases in a generic and universal manner. LOD is based, in fact, on a reconsideration of the concept of the database. It may be claimed that databases always consist of certain fields and of certain values for these fields. These values typically describe certain topics. Consider the following description of a painting, for example.
Creator: Leonardo da Vinci
Title: Mona Lisa
Material: Oil on Poplar Panel
Dimensions: 77 cm × 53 cm
As you can see, this description makes four statements about the painting. For each of these statements, we can distinguish three components: (1) The description is about a certain resource. In this case, the statements are all about a specific work of art. (2) the description focuses on a certain characteristic or property of this resource. The statements in this example focus on the creator, the title, the material and the dimensions. (3) The statements describe the resource using certain values. The first statement in the example above asserts that this painting was created by Johannes Vermeer.
This view that descriptive statements always consist of three basic components also forms the core of the model that underpins the Resource Description Framework (RDF), one of the central technologies of the Semantic Web. RDF is a framework for representing descriptions of resources, and it enables us to represent these statements in a standardised way. RDF assumes that we can always distinguish three components within all the statements that can be made in a database. To reiterate, there is always an entity that is being described. This entity is described using a property. Thirdly, we supply a value for this property. The RDF standard uses specific terms for these three components: Subject, Predicate and Object. It is claimed, furthermore, that any statement that we can make can ultimately be formulated using this basic format consisting of three parts. We also refer to these types of statements as triples.
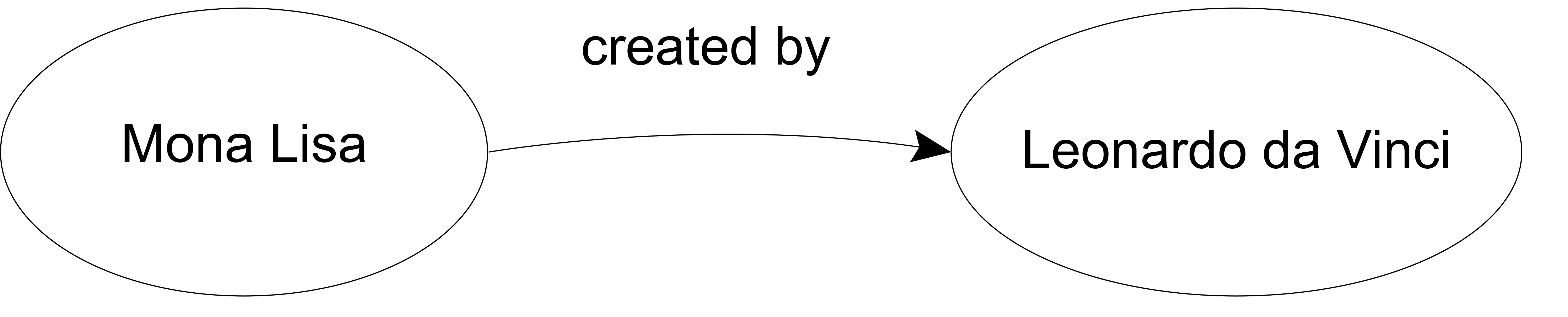
Following the logic of RDF, we can formulate the following triple about the painting entitled “Mona Lisa”:
"Mona Lisa" "created by" "Leonardo da Vinci" .
Triples can also be represented visually. In this example, we see 1) the subject (‘Mona Lisa’), followed by 2) the predicate (‘created by’) and 3) the object (‘Leonardo da Vinci’).
Exercise 1#
As mentioned, the engineers who developed the Semantic Web claimed that any statement can be represented as a triple, consisting of a subject, a predicate and an object. To familiarise yourself with this model, choose a certain work of art (e.g. a novel, a painting or a statue) and try to express what you know about this work of art using triples only. For now, simply surround the subjects, the predicates and the objects with quotes (“’”), and end the triples with a full stop (‘.’)
For example:
"Mona Lisa" "created by" "Leonardo Da Vinci" .
"Mona Lisa" "depicts" "Lisa del Giocondo" .
Uniform Resource Identifiers#
Databases often contain statements about named entities, such as people, places or organisations. Such names can often be written in many different ways. A last name may be followed by a last name, or the other way around. Foreign names may also be transcribed or transliterated in different ways. The name of the Russian author Fjodor Dostojevski, for example, has been spelt in many different ways. There is also the problem of name ambiguity. Names are not unique. Jack Straw is both the name of a fourteenth-century English rebel and a UK cabinet minister prominent in Tony Blair’s administration. One person may also be known under different names, and names may also change, following a marriage, for example.
Problems such as these can be solved by working with identifiers. The central idea is that we do not work with the actual name of a person, as this name may lead to ambiguities. Instead, we provide a code that is globally unique. Many organisations have already assigned such codes to people. Virtual International Authority File (VIAF), for example, is a resource in which many existing thesaurus records have been brought together in a vast overarching database. In VIAF’s search interface, you can search for specific people. In the list of results, you can find the identifiers that have been assigned to these people. VIAF additionally stores many of the spelling variants that have been found for specific names. in VIAF, the minister Jack Straw was assigned idenifier 64183282, and the fourteenth-century English rebel named Jack Straw was assigned identifier 33059614.
Names of people, organisations and geographic locations can likewise be found in WikiData.
The identifiers that have been created by organisations such as VIAF and WikiData can be referred to as Uniform Resource Identifiers (URI). An URI, simply put, is a code consisting of characters or numbers that is used to identify a resource on the web. There are two types of URIs. a Uniform Resource Locator (URL), firstly, specifies the address of a resource on the web. A URL also specifies how the resource can be retrieved, through a reference to a protocol such as HTTP. A Uniform Resource Name (URN), secondly, only assigns a name or a code to the resource. It does not imply that the resource can also be retrieved. A URI, in short, can identify an entity through its location, its name, or both. URIs have been created for all kinds of entities, including people, publications, historical events, plants, locations and works of art.
A URI first and foremost identifies a certain entity, in a unique, consistent and unambiguous way. The URI https://www.wikidata.org/wiki/Q41264, for example, identifies the painter Johannes Vermeer. Obviously, the entities that are identified using an URI cannot always be retrieved via the web. This would be possible with the URIs created for web pages, but not with the URIs created for people or for locations. Organisations creating such URIs for named entities (locations, people and organisations, etc.) are encouraged, however, to create so-called HTTP URIs. This means that the URI can be resolved to a web page which supplies meaningful information about the resource being identified. When you open the URI for https://www.wikidata.org/wiki/Q41264 on WikiData, you can see a page containing many details about the painter being identified, Johannes Vermeer. This process is referred to as resolution. Resolving a URI means that the user is redirected to page supplying relevant information.
URIs such as these can also be used in RDF triples. The great advantage of working with URIs is that they can provide stable and consistent references to resources.
Exercise 2#
Revisit the triples that you had formulated for exercise 1. Try to replace the strings in the objects and the subjects (i.e. the characters surrounded by quotes) with URIs. URIs should be given in angular brackets.
Examples of URIs can be found at the following websites:
On WikiData, the URIs consist of the domain name starting with https://www.wikidata.org/wiki followed by a Q-ID (the unique identifier of a data item on Wikidata, comprising the letter “Q” followed by one or more digits). For example:
<https://www.wikidata.org/wiki/Q12418> <was painted by> <https://www.wikidata.org/wiki/Q762> .
Namespaces#
It good to know that, when you work with URIs, they can be abbreviated. If you always include the full URI, the triples can become very long and somewhat cumbersome. To abbreviate URIs, you firstly need to define one or more prefixes. A prefix consists of a code, associated with a base URI. A base URI is the first part of the full URI which all the URIs created by a certain organisation have in common. The base URI for WikiData is “https://www.wikidata.org/wiki/”. These base URIs are also referred to as namespaces.
Using namespaces, the sample triple that was given in exercise 2 can be abbreviated as follows.
wiki: <https://www.wikidata.org/wiki/>
<wiki:Q12418> <was painted by> <wiki:Q762> .
Vocabularies#
As was discussed above, the references to people and to organisations can be made more persistent and more consistent when we work with URIs. We can use these URIs in triples as subjects and as objects. Using a similar mechanism, the properties in our RDF statements can be provided as URIs as well.
Numerous organisations have formulated vocabularies with terms that can be used as predicates. Such predicates are specific types of resources that can describe the relationships between resources, such as “painted by”, “located in” or “collected by”. Like all web resources, predicates are identified via URIs.
Such properties are typically part of a larger system which we can refer to as ontology. In the field of philosophy, ontology usually denotes the study of all things that are known to exist. In knowledge representation systems, the term has also been used to refer to the categories that use to divide this known reality into groups, as well as to the relationships that can exist between these categories. When we classify entities and describe relations, this gives us a systematic way to organize knowledge and grasp the reality surrounding us. The Linnaean taxonomy, for example, as proposed in the Systema Naturae (1735) similarly tried to organise the natural world systematically into kingdoms (the Animal, Vegetable and Mineral Kingdoms), classes, orders and genera, and eventually this system was used to classify the individual species. Such a classification system helps us to understand the nature singular entities.
In the context of the semantic web, Schema.org and Dublin Core may be viewed as examples of such ontologies. They provide a list of all the entities within a certain domain, and they also provide a standardised vocabulary with which we can describe these entities and the relations between these. The relationships between subjects and objects can be described using terms provided by ontologies.
Consider the triple below, which states that the Mona Lisa was painted by Leonardo da Vinci.
<wiki:Q12418> “was created by” <wiki:Q762> .
We can represent the predicate in this triple using a property named http://purl.org/dc/terms/created, which has been defined in Dublin Core.
<wiki:Q12418> <dc:creator> <wiki:Q762> .
Note that the triple also includes a prefix, which shortens the reference to the dublin core namespace. For heritage institutions to be able to share their data, it is essential that they use the same formal language to describe concepts and relationships. For the documentation of cultural heritage, CIDOC CRM {https://www.cidoc-crm.org/} offers guidelines on how to describe heritage information across museums, libraries and archives.
Properties are essential for building relationships between two data elements. When we make use of shared vocabularies such as Shcema.org, Dublin Core or CIDOC CRM, the RDF data also becomes more reusable and more interoperable.
Exercise 3#
For al the predicates in the triples you formulated for exercise 1 and 2, find suitable URIs. If necessary, you can find properties and namespaces by searching on the Linked Open Vocabularies website. When you search for specific terms in the search field at the top of the screen, the website will try to list the terms that are most similar to the term you provided. Note that, on this website, properties are distinguishes visually form other types of resources through a blue bar.
Serialisation#
RDF triples can be written in different ways. The type of notation that was recommended in exercises 1 and 2, is called Turtle, which stands for Terse RDF Triple Language. In this format, the subject, predicate and object are separated by spaces, and the triples need to end in a full stop. Turtle also stipulates that URIs need to be provided in angular brackets and that strings need to be given in quotes. The term ‘serialisation’ refers to the specific format in which the RDF data has been encoded. It is roughly similar to the term ‘format’. Other formats for RDF include RDF/XML and JSON-LD.
Graphs#
LOD, in sum, is a technology for harmoning databases. Concretely, it means that data need to be expressed using the RDF data model, which assumes that all descriptive statements can be expressed as collections of subjects, predicates and objects. Through this system, data values can be provided alongside explicit descriptions of these values.
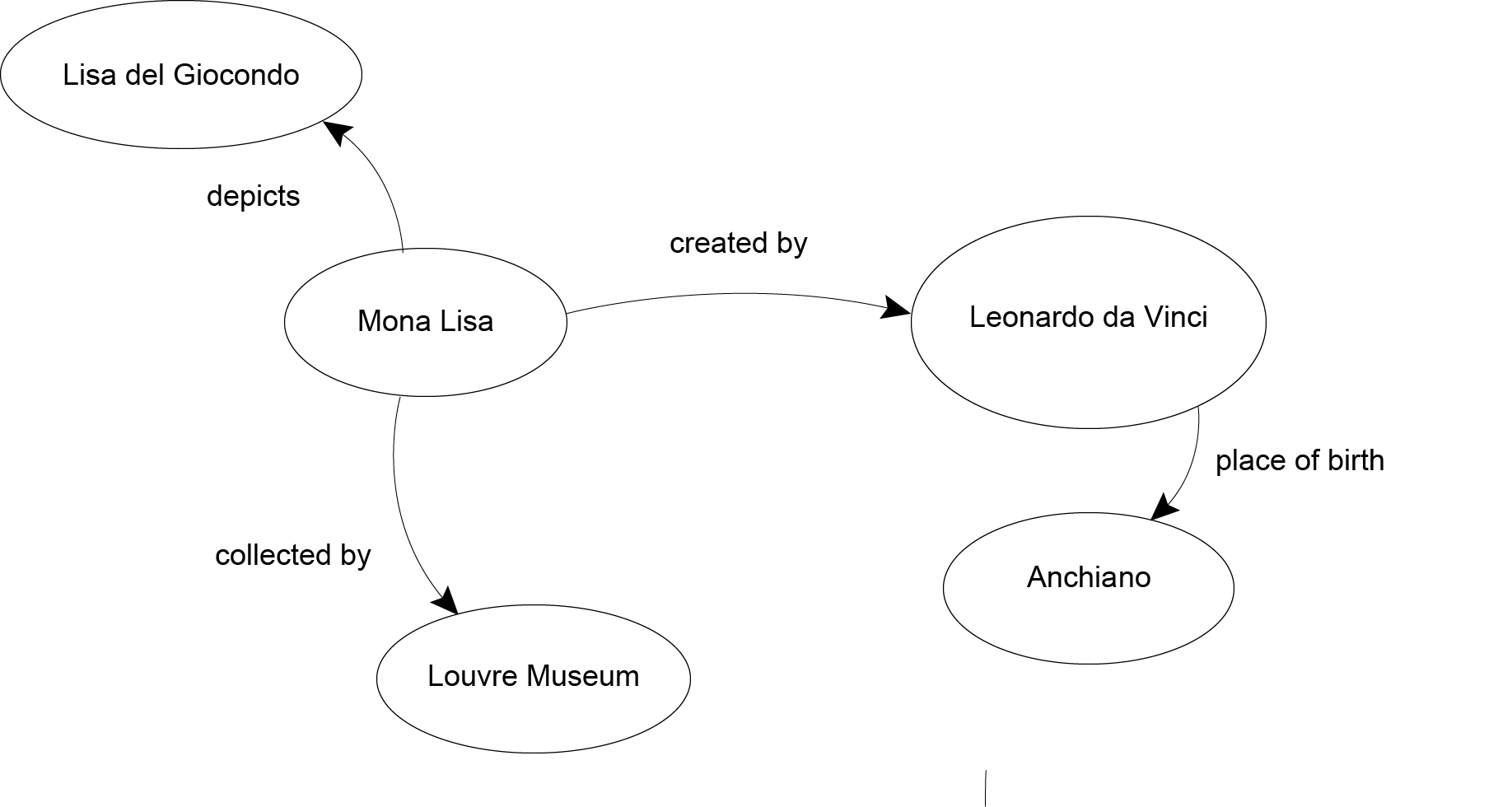
When you have a collection of triples, they collectively form a graph. The triples in such graphs can result in intricate skeins of relationships. One URI can be involved in many different triples. The object of one triple can form the subject of another triple, and vice versa. The graphs that results from such connections can take any shape and they can continue to grow. In RDF triples, things can be related to each other in complicated ways and without being fixed. Triples of resources can be grouped and regrouped endlessly.
Applications in cultural heritage#
The possibilities associated with the semantic web can also be applied usefully within the domain of cultural heritage. By making use of LOD, Data collections from different institutions can be connected and searched simultaneously.
ResearchSpace is a platform initiated by the British Museum. It forms a good illustration of the potential of LOD in the context of cultural heritage. ResearchSpace aims to connect the information managed by various museums in London using Linked Open Data. On the platform, the networks that are created using RDF ttiples are referred to as ‘Knowledge Graphs’.
display(IFrame('https://player.vimeo.com/video/540172221?h=51d3108111' , width = 640 , height = 360 ))
Late Hokusai is one of the projects conducted on the ResearchSpace platform. In this project, the British Museum and SOAS (University of London) created an online resource based on LOD to collect data about the Japanese artist Katsushika Hokusai (1760-1849). the researchers have accumulated materials from various collections, creating a network of information available to anyone who is interested.